Understanding LLMs & Multimodal AI
Generating Accurate Responses to Prompts
Author: Ariel Wadyese x OpenAi Deep Research Mode

Large Language Models (LLMs) and newer multimodal AI systems have revolutionized how we interact with machines, producing remarkably accurate and context‑aware responses from prompts. This report gives a developer‑focused overview of: prompt processing (tokenization, embeddings, attention, transformer architecture), training and fine‑tuning (including RLHF and evaluation), mechanisms driving accuracy and relevance, the evolution from text‑only to multimodal models, and examples across text, images, audio/music, video, and code. Clear explanations and diagrams are included.
When a user inputs a prompt, the model first performs tokenization, breaking text into tokens (words or subword units). Each token is mapped to a numeric embedding vector from an embedding table; positional information is added to preserve order. These vectors form the input to stacked Transformer layers where self‑attention contextualizes each token using information from the entire sequence.
Self‑attention computes relevance between all token pairs using queries, keys, and values, aggregating context with learned weights. Multiple heads in parallel capture varied relations (syntax, semantics), enabling robust long‑range reasoning and disambiguation.
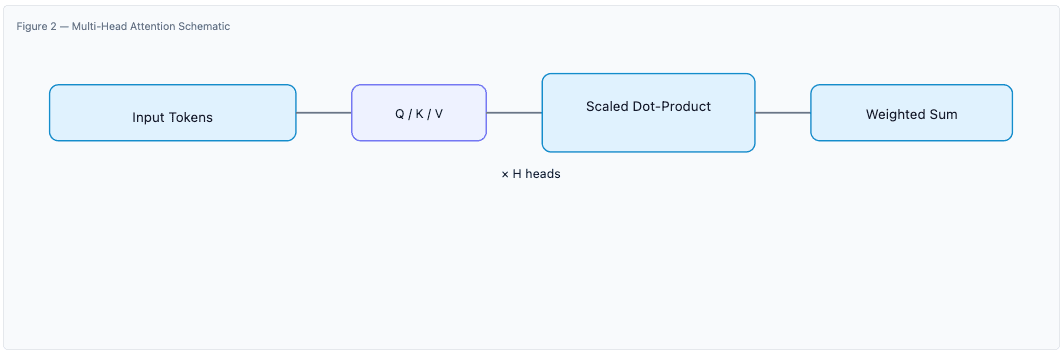
The Transformer stacks blocks composed of multi‑head self‑attention and position‑wise feed‑forward networks, wrapped with residual connections and normalization for stability. Decoder‑only models (e.g., GPT) apply masked attention to generate tokens autoregressively.
Given “The programmer put the book on the table because it was old,” attention for “it” peaks at “the book,” resolving the pronoun, while later evidence (“old”) contributes context. These learned patterns enable accurate disambiguation.
Pre‑training. Models are trained with next‑token prediction over vast corpora (e.g., web, books, Wikipedia), learning grammar, facts, and reasoning patterns without explicit labels.
Supervised Fine‑Tuning (SFT). Curated prompt→response pairs (often human‑written) teach instruction following, tone, and dialogue patterns.
RLHF. Human preference rankings train a reward model; policy optimization (e.g., PPO) steers responses toward helpfulness, harmlessness, and honesty.
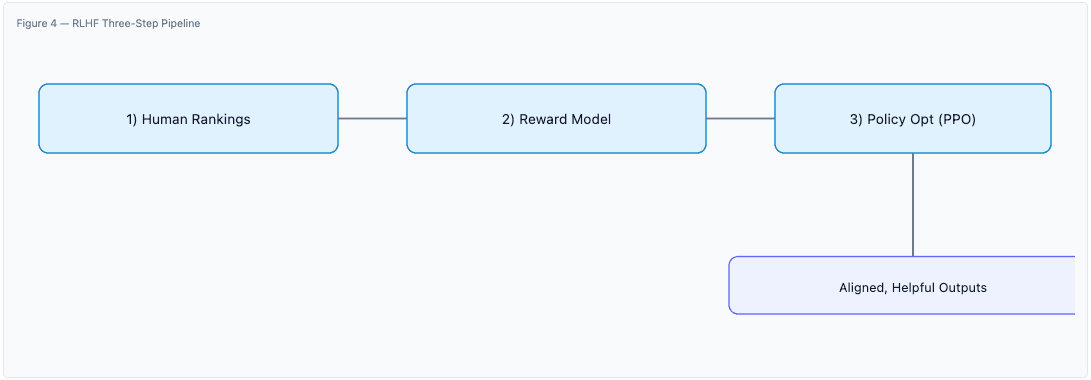
Automated metrics (e.g., perplexity) assess language modeling quality, while human evaluation, red‑teaming, and domain benchmarks probe helpfulness, correctness, coherence, and safety. Feedback‑driven iteration targets failure modes (e.g., hallucinations) with additional tuning or data.
- Attention & Long Context: Integrates distant details across long prompts and multi‑turn chats.
- Scale: Larger parameter counts and data improve generalization and factual coverage.
- Data Quality & Diversity: Curated corpora reduce gaps, bias, and drift.
- SFT & RLHF: Optimize for human‑preferred answers and on‑topic behavior.
- Continuous Evaluation: Iterative updates close capability gaps.
Transformers generalize beyond text by tokenizing non‑text modalities: image patches (ViT), audio frames/spectrograms, and video spatio‑temporal tokens. The same attention machinery models relationships across these token sequences.
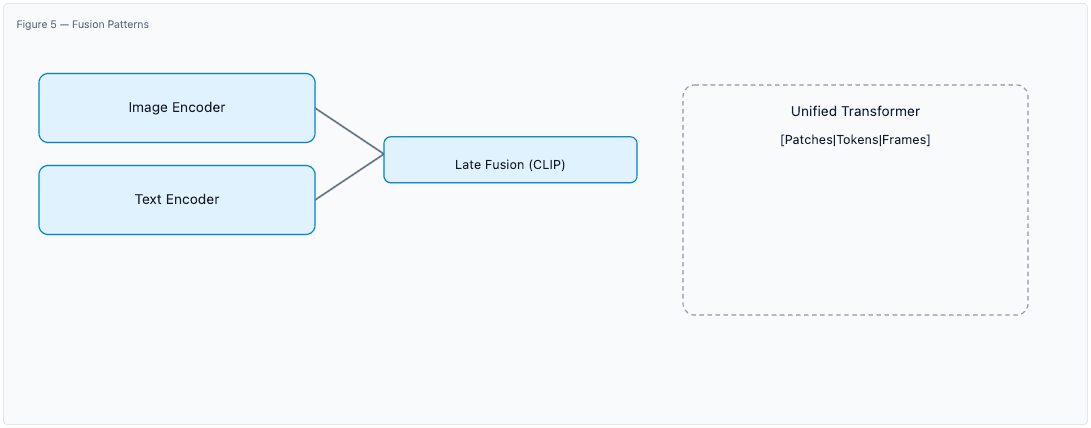
- Separate Encoders & Late Fusion (e.g., CLIP): Modality‑specific encoders produce embeddings that are aligned/combined.
- Unified Multimodal Transformer: Serialized mixed tokens (image patches + text) enable early fusion and cross‑modal attention.
- Cross‑Attention (Encoder→Decoder): One modality conditions generation in another (e.g., image captioning, text‑to‑image).
Capabilities include image description, VQA, text→image generation, ASR and TTS, grounding for robots, and cross‑modal transfer (e.g., describe a diagram, answer a spoken question, and return a textual rationale).
- Text→Image: DALL·E, Stable Diffusion, Imagen — diffusion models refine noise toward images consistent with text prompts.
- Text→Music/Audio: Jukebox, MusicLM — hierarchical generation of musical/audio tokens aligned to descriptions; TTS for speech.
- Text→Video: Make‑A‑Video, Imagen Video, Phenaki‑style approaches — short clips with learned motion dynamics.
- Code Generation: Codex, StarCoder — NL specs to compilable/runnable code; translation across languages; IDE assistance.
LLMs convert tokenized text into contextual representations via attention and generate answers token‑by‑token. Scale, high‑quality data, and alignment (SFT+RLHF) drive accuracy and relevance. Extending Transformers across modalities enables unified systems that read, see, listen, and generate across text, images, audio, video, and code.
- Vaswani et al. (2017) — Attention Is All You Need.
- OpenAI model cards & technical blogs — GPT‑3, Codex, DALL·E, CLIP.
- Google research — ViT, ViLT, MusicLM, Imagen/Video.
- Industry write‑ups on RLHF, evaluation, and safety.